Pandas 便利
便利なんですが。。 Pythonにはdictがあったり、JSONなど他の形式のファイルを読み込みたいこともあるんですが、ときどき、エラーでて時間食ったりするので。。その忘備録として。。
行と列が全部そろってないと駄目
import pandas as pd
data = {'name': ['nick', 'david', 'joe', 'ross'],
'age': ['5', '10', '7', '6']}
こういう行・列がそろっているやつは、
new = pd.DataFrame.from_dict(data)
で、読み込めて
| index | name | age |
|---|---|---|
| 0 | nick | 5 |
| 1 | david | 10 |
| 2 | joe | 7 |
| 3 | ross | 6 |
と入りますが。。
data = {'name': ['nick', 'david', 'joe', 'ross'],
'age': ['5', '10', '7', '6'],
'point':['1','2']}
こういう行と列が揃ってない時は、
ValueError: arrays must all be same length
とか出てできません。
データを例えば、行数を揃えてあげる
data['point'].append("NaN")
data['point'].append("NaN")
とか。。
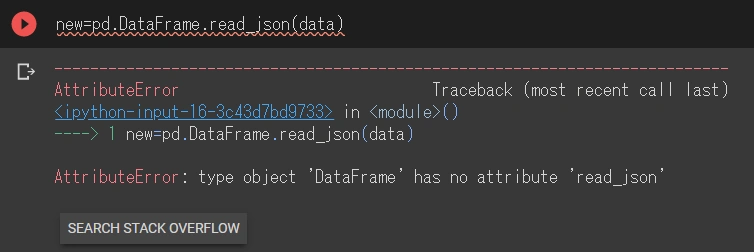
JSONとかでも。。
pd.read_json()
でも、同様なので、行列あわせたり、入れ子のものは直接読み込めない。
https://pandas.pydata.org/pandas-docs/version/1.1.3/reference/api/pandas.read_json.html
半構造化JSONデータをフラットテーブルに正規化
pd.json_normalize() ー>単に入れ子の場合とかいろいろできる。
https://pandas.pydata.org/docs/reference/api/pandas.json_normalize.html
JSON文字列を辞書に変換
json.loads()
JSONファイルを辞書として読み込み
json.load()
等を駆使しないといけない
ここのノートが詳しいです。
https://note.nkmk.me/python-json-load-dump/
で。。なんでこんなの書いたかというと、WindyのAPIの戻り値がJSONなんだけど
辞書型Dictでしか読めなかったので、DataFrameに変換したからなのです(笑)
Windy APIのPoint forecastを使ってみたい方は、こちらから(笑)
https://github.com/tom2rd/lightningUAVs/blob/main/WINDYAPI/windyapi_uchinada.ipynb

コメントを残していただけるとありがたいです