SEO
昨日は、Google文化圏って凄いなぁ~って思って、あれの最初ってなんだったかな?なんて・・ そういえばPageRankだったかな? 今だとSEOって言われる。
SEOは、Search Engine Optimization” の略ですね。昔はYahooやらAltaVistaとかいろんな検索エンジンがあって、そいつらに登録したりして・・だったのですが、今やGoogle文化圏では、もうGoogle一色ですね。その検索エンジン最適化を意味する言葉で、 検索結果で上位に来るようにして、Webサイトがより多く露出されるようにしようとするものですね。
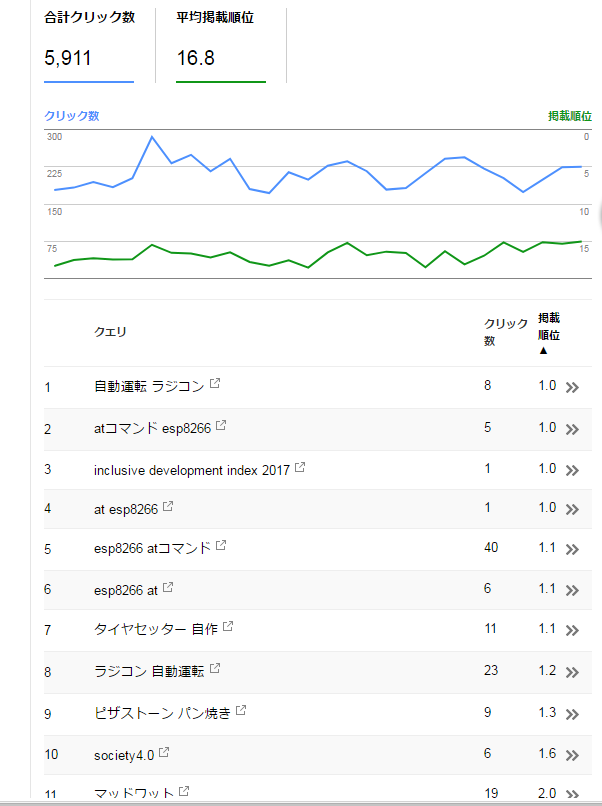
ちなみに・・このHPのここ28日間の平均掲載順位は16.8位。。
https://tom2rd.sakura.ne.jp/tominaga/rc/
とかの膨大なページやらもあるから・・ ラジコン・電子工作に強いのかな?(笑)

でも肝心なのは、このHPを見て何か行動を起こす(クリックするとか)ことだら、本当は、クリック数の方が重要なんでしょうけど、ここは、掲載順位が10位くらいでも、クリックが一番多かったりしますね。

表示回数で行くと、いとおかし というビックキーワード?(笑)で掲載順位が9位くらいのものの方が表示回数が多くなるので、よく言われるキーワード選定って、本当は重要なんでしょうね。

よく言われているような、キーワード選定とか、descriptionタグとかSEO対策は、このHPでは、全くしていません(笑)。
SEO対応する人は、Googleがガイドを出してくれているので、それに従うのが本当は一番なんでしょう。
https://support.google.com/webmasters/answer/35291?hl=ja
クリックしてsearch-engine-optimization-starter-guide-ja.pdfにアクセス
対策に興味のある人は、日本語のやつより、英語のやつを読む方がいいような気がします。
究極のGoogleアルゴリズムチートシート
http://neilpatel.com/blog/the-ultimate-google-algorithm-cheat-sheet/
Googleランキングファクター 200:完全なリスト
http://backlinko.com/google-ranking-factors
などなど。。 って、そっちの話でなく。。
最初のGoogleのページランク
ラリーペイジが書いたThe PageRank Citation Ranking: Bringing Order to the Webという論文があります。1998年ですね。
アブストラクト(概要)には、以下のように書かれています。
Webページの重要性は、読者の関心、知識、態度に依存する本質的な副次的事項です。 しかし、Webページの相対的重要性については、依然として多くのことが言えます。 本稿では、人間の関心と注目を的確に測定するために、Webページを客観的かつ機械的に評価する方法であるPageRankについて述べる。 私たちはPageRankを理想化されたランダムなWebサーファーと比較します。 多数のページに対してPageRankを効率的に計算する方法を示します。 そしてPageRankを検索とユーザーの操作に適用する方法を示します
Webサーファーと比較しているっていうのは面白いですね。当時はサーフィングって言ってました(笑)
そう言えば、少しあとですが、こういう本も出ていて、
これを読んでワクワクというより、ドキドキしたものです。HDDを大量に買ってどれが壊れやすいか?なんてことも論文にしたりして、ものすごく実用的な論文になっていて、日本では当時は、そんなのは論文にならん!って怒られたりしました。やはり実装よりのことを真剣にしないとだめなんですよねぇ~
同じ時期に実装についても、出ていて、「大規模ハイパーテキストWeb検索エンジンの解剖」という論文もあります。
同じように概要は、
本稿では、ハイパーテキストに存在する構造を大量に利用する大規模な検索エンジンのプロトタイプであるGoogleを紹介する。 Googleは、Webを効率的にクロールしてインデックスを作成し、既存のシステムよりもはるかに満足できる検索結果を生成するように設計されています。少なくとも2400万ページのフルテキストとハイパーリンクデータベースを備えたプロトタイプはhttp://google.stanford.edu/にあります。検索エンジンを設計することは難しい作業です。検索エンジンは、数千から数百万のWebページにインデックスを付け、それに匹敵する数の異なる用語を使用します。彼らは毎日何千万もの質問に答える。 Web上での大規模検索エンジンの重要性にもかかわらず、学術研究はほとんど行われていません。さらに、テクノロジーとWebの急速な普及により、今日のWeb検索エンジンの作成は3年前とは非常に異なっています。このホワイトペーパーでは、大規模なWeb検索エンジンの詳細な説明を提供します。従来の検索技術をこの規模のデータに拡大するという問題の他に、より良い検索結果を得るためにハイパーテキストに存在する追加情報を使用することに伴う新たな技術的課題がある。この論文では、ハイパーテキストに存在する追加情報を利用できる実用的な大規模システムを構築する方法についてのこの問題に取り組んでいます。また、誰もが望むものを公開することができる、コントロールされていないハイパーテキストコレクションを効果的に処理する方法の問題を見ていきます。
ビルクリントンと入力して出てくるページをサンプルに入れています。

面白いですよね。というか、懐かしい。
で・・・検索での課題は、以下のようにつづられています。
今日のウェブ検索エンジンのユーザーが直面している最大の問題は、結果の質です。結果は面白いことが多く、ユーザーの視野を広げる一方で、しばしばイライラして貴重な時間を消費します。たとえば、最も人気のある商用検索エンジンの1つで「ビル・クリントン」を検索した結果の最高の結果は、1997年4月14日のビル・クリントン・ジョークであった。Googleは、ウェブが継続するほど質の高い検索を提供するように設計され、情報を容易に見つけることができる。これを達成するために、Googleはリンク構造とリンク(アンカー)テキストからなるハイパーテキスト情報を大量に使用しています。また、Googleは近いフォント情報も使用します。検索エンジンの評価は困難ですが、Googleは現在の商用検索エンジンよりも高品質の検索結果を返すことに主観的に気付いています。 PageRankによるリンク構造の分析により、Googleはウェブページの品質を評価することができます。リンクが何を指しているかの説明としてリンクテキストを使用すると、検索エンジンは関連性の高い(ある程度の高品質の)結果を返すのに役立ちます。最後に、近接情報を使用すると、多くのクエリで関連性が大幅に向上します
きちんと内容を見て表示させていきたいという意図がありますね。
だから、自然言語処理や、機械学習を進めていったのでしょうね。そのためのスケーラビリティとかの技術も高めていったんでしょう。
ランク計算の基本になるのは、Google-Matrix という行列計算
今は、もう本当に複雑なアルゴリズムになっているんでしょうけど、昔の文献を読むと、Google マトリックスというものが出てきて、相互リンクの計算になっていますね。
クリックしてslides_dagstuhl07071.pdfにアクセス
クリックしてDynneson_FinalDraft_Linear-Algebra-Project.pdfにアクセス
こういう計算を早くしようと思うと、今はやりの機械学習にも使われるTensorFlowとかは、結構昔から実は検討されていたんじゃないのかな?なんて思ったりしました。
今では、TPUとかいうDeeplearning用のアクセラレータまであるんですから。。凄いですねぇ~
https://research.googleblog.com/search/label/TensorFlow
そいういう意味では、Googleは、機械学習で、ページランクも再発明をしているのかもしれませんね。文脈を理解したりしだしていますし・・多くの言語を翻訳したりしてますし、アシスタントという機能も日本語でもできるようにしてきましたからねぇ~ 凄いなぁ
https://japan.googleblog.com/2017/05/google-assistant.html
コメントを残していただけるとありがたいです