Encode
これまであんまりはまったことなかったんだけど。。
ファイルにはCodecってのがあります(笑)
https://docs.python.org/3/library/codecs.html
計測器から吐き出すCSVファイルって、エンコードなしとかだったりするのね。
---------------------------------------------------------------------------
UnicodeDecodeError Traceback (most recent call last) Cell In[3], line 4 1 import numpy as np 3 with open('data/50OHM.CSV') as f:
----> 4 print(f.read())
File :322, in decode(self, input, final)
UnicodeDecodeError: 'utf-8' codec can't decode byte 0x96 in position 11: invalid start byte
Pythonでそのまま読もうとすると。。こういうエラーがでて、
encode=’shift-jis’ でも読めなかったりしました。。メモ帳でみると’ANSI’てなってるので、
指定しても読めない。。
手当たりしだいやるか? って言っても。。こんなにあるんですよね(笑)
| Codec | Aliases | Languages |
|---|---|---|
| ascii | 646, us-ascii | English |
| big5 | big5-tw, csbig5 | Traditional Chinese |
| big5hkscs | big5-hkscs, hkscs | Traditional Chinese |
| cp037 | IBM037, IBM039 | English |
| cp273 | 273, IBM273, csIBM273 | German
New in version 3.4. |
| cp424 | EBCDIC-CP-HE, IBM424 | Hebrew |
| cp437 | 437, IBM437 | English |
| cp500 | EBCDIC-CP-BE, EBCDIC-CP-CH, IBM500 | Western Europe |
| cp720 | Arabic | |
| cp737 | Greek | |
| cp775 | IBM775 | Baltic languages |
| cp850 | 850, IBM850 | Western Europe |
| cp852 | 852, IBM852 | Central and Eastern Europe |
| cp855 | 855, IBM855 | Bulgarian, Byelorussian, Macedonian, Russian, Serbian |
| cp856 | Hebrew | |
| cp857 | 857, IBM857 | Turkish |
| cp858 | 858, IBM858 | Western Europe |
| cp860 | 860, IBM860 | Portuguese |
| cp861 | 861, CP-IS, IBM861 | Icelandic |
| cp862 | 862, IBM862 | Hebrew |
| cp863 | 863, IBM863 | Canadian |
| cp864 | IBM864 | Arabic |
| cp865 | 865, IBM865 | Danish, Norwegian |
| cp866 | 866, IBM866 | Russian |
| cp869 | 869, CP-GR, IBM869 | Greek |
| cp874 | Thai | |
| cp875 | Greek | |
| cp932 | 932, ms932, mskanji, ms-kanji | Japanese |
| cp949 | 949, ms949, uhc | Korean |
| cp950 | 950, ms950 | Traditional Chinese |
| cp1006 | Urdu | |
| cp1026 | ibm1026 | Turkish |
| cp1125 | 1125, ibm1125, cp866u, ruscii | Ukrainian
New in version 3.4. |
| cp1140 | ibm1140 | Western Europe |
| cp1250 | windows-1250 | Central and Eastern Europe |
| cp1251 | windows-1251 | Bulgarian, Byelorussian, Macedonian, Russian, Serbian |
| cp1252 | windows-1252 | Western Europe |
| cp1253 | windows-1253 | Greek |
| cp1254 | windows-1254 | Turkish |
| cp1255 | windows-1255 | Hebrew |
| cp1256 | windows-1256 | Arabic |
| cp1257 | windows-1257 | Baltic languages |
| cp1258 | windows-1258 | Vietnamese |
| euc_jp | eucjp, ujis, u-jis | Japanese |
| euc_jis_2004 | jisx0213, eucjis2004 | Japanese |
| euc_jisx0213 | eucjisx0213 | Japanese |
| euc_kr | euckr, korean, ksc5601, ks_c-5601, ks_c-5601-1987, ksx1001, ks_x-1001 | Korean |
| gb2312 | chinese, csiso58gb231280, euc-cn, euccn, eucgb2312-cn, gb2312-1980, gb2312-80, iso-ir-58 | Simplified Chinese |
| gbk | 936, cp936, ms936 | Unified Chinese |
| gb18030 | gb18030-2000 | Unified Chinese |
| hz | hzgb, hz-gb, hz-gb-2312 | Simplified Chinese |
| iso2022_jp | csiso2022jp, iso2022jp, iso-2022-jp | Japanese |
| iso2022_jp_1 | iso2022jp-1, iso-2022-jp-1 | Japanese |
| iso2022_jp_2 | iso2022jp-2, iso-2022-jp-2 | Japanese, Korean, Simplified Chinese, Western Europe, Greek |
| iso2022_jp_2004 | iso2022jp-2004, iso-2022-jp-2004 | Japanese |
| iso2022_jp_3 | iso2022jp-3, iso-2022-jp-3 | Japanese |
| iso2022_jp_ext | iso2022jp-ext, iso-2022-jp-ext | Japanese |
| iso2022_kr | csiso2022kr, iso2022kr, iso-2022-kr | Korean |
| latin_1 | iso-8859-1, iso8859-1, 8859, cp819, latin, latin1, L1 | Western Europe |
| iso8859_2 | iso-8859-2, latin2, L2 | Central and Eastern Europe |
| iso8859_3 | iso-8859-3, latin3, L3 | Esperanto, Maltese |
| iso8859_4 | iso-8859-4, latin4, L4 | Baltic languages |
| iso8859_5 | iso-8859-5, cyrillic | Bulgarian, Byelorussian, Macedonian, Russian, Serbian |
| iso8859_6 | iso-8859-6, arabic | Arabic |
| iso8859_7 | iso-8859-7, greek, greek8 | Greek |
| iso8859_8 | iso-8859-8, hebrew | Hebrew |
| iso8859_9 | iso-8859-9, latin5, L5 | Turkish |
| iso8859_10 | iso-8859-10, latin6, L6 | Nordic languages |
| iso8859_11 | iso-8859-11, thai | Thai languages |
| iso8859_13 | iso-8859-13, latin7, L7 | Baltic languages |
| iso8859_14 | iso-8859-14, latin8, L8 | Celtic languages |
| iso8859_15 | iso-8859-15, latin9, L9 | Western Europe |
| iso8859_16 | iso-8859-16, latin10, L10 | South-Eastern Europe |
| johab | cp1361, ms1361 | Korean |
| koi8_r | Russian | |
| koi8_t | Tajik
New in version 3.5. |
|
| koi8_u | Ukrainian | |
| kz1048 | kz_1048, strk1048_2002, rk1048 | Kazakh
New in version 3.5. |
| mac_cyrillic | maccyrillic | Bulgarian, Byelorussian, Macedonian, Russian, Serbian |
| mac_greek | macgreek | Greek |
| mac_iceland | maciceland | Icelandic |
| mac_latin2 | maclatin2, maccentraleurope, mac_centeuro | Central and Eastern Europe |
| mac_roman | macroman, macintosh | Western Europe |
| mac_turkish | macturkish | Turkish |
| ptcp154 | csptcp154, pt154, cp154, cyrillic-asian | Kazakh |
| shift_jis | csshiftjis, shiftjis, sjis, s_jis | Japanese |
| shift_jis_2004 | shiftjis2004, sjis_2004, sjis2004 | Japanese |
| shift_jisx0213 | shiftjisx0213, sjisx0213, s_jisx0213 | Japanese |
| utf_32 | U32, utf32 | all languages |
| utf_32_be | UTF-32BE | all languages |
| utf_32_le | UTF-32LE | all languages |
| utf_16 | U16, utf16 | all languages |
| utf_16_be | UTF-16BE | all languages |
| utf_16_le | UTF-16LE | all languages |
| utf_7 | U7, unicode-1-1-utf-7 | all languages |
| utf_8 | U8, UTF, utf8, cp65001 | all languages |
| utf_8_sig | all languages |
Chardet
Chardet: The Universal Character Encoding Detector
https://pypi.org/project/chardet/
で。。解明する! ってやってみたけど。。ダメだった。
import chardet filepath = "data/SSP4 L1.CSV" with open(filepath, 'rb') as f: c = f.read() result = chardet.detect(c) print(result)
とすると。。
{'encoding': None, 'confidence': 0.0, 'language': None}
ということで。。
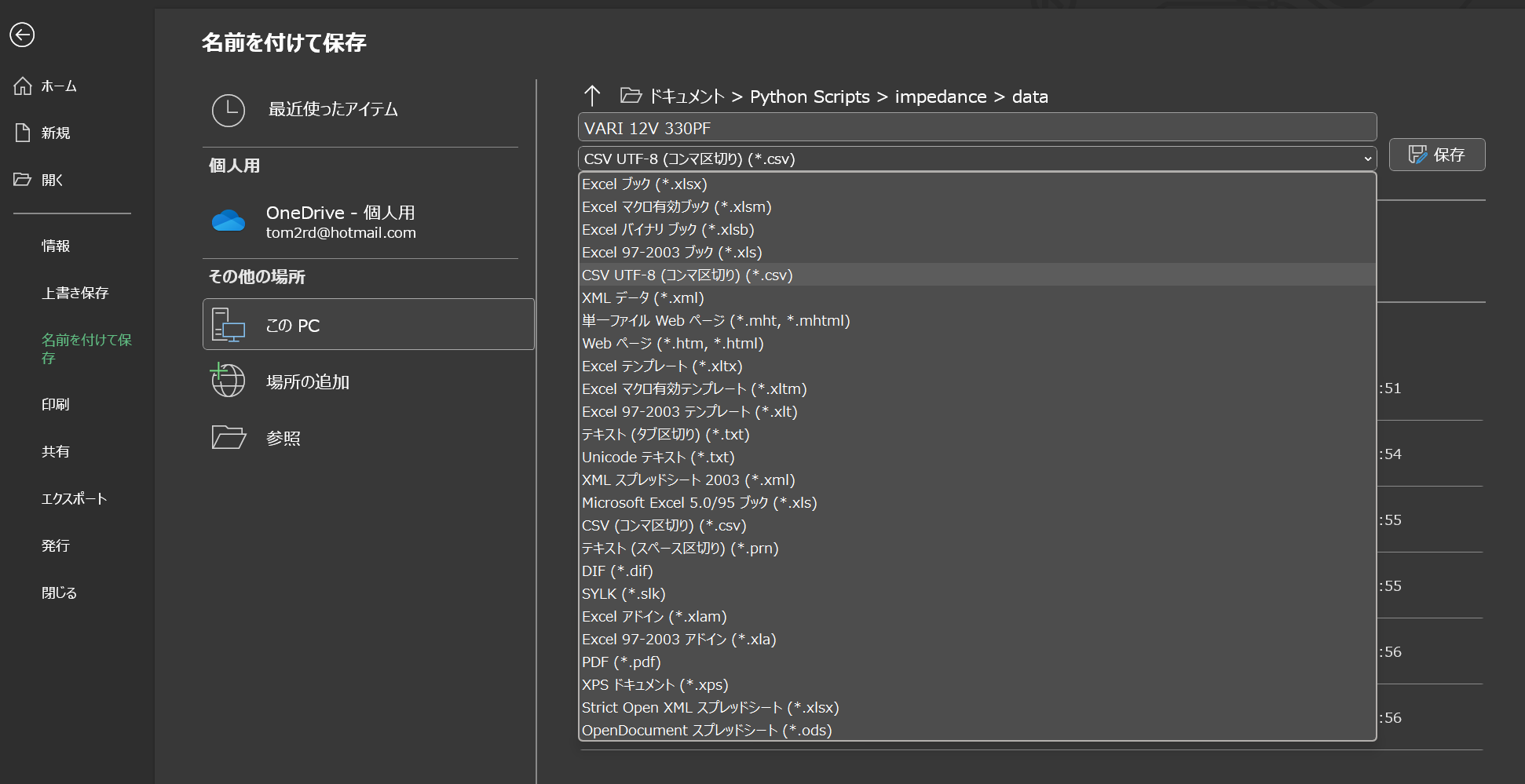
ExcelでUTF-8で書き出せるのね!
簡単なのは、Excelで読めるなら。。ExcelでCSVで保存すると。。UTF-8コンマ区切りってあるんですね!知らんかった。。

これ簡単w
ちなみに、chardetで見てみると。。
{'encoding': 'UTF-8-SIG', 'confidence': 1.0, 'language': ''}
Excelとかとのやり取りの場合は、UTF-8-SIG が正解なのかもしれない。
コメントを残していただけるとありがたいです