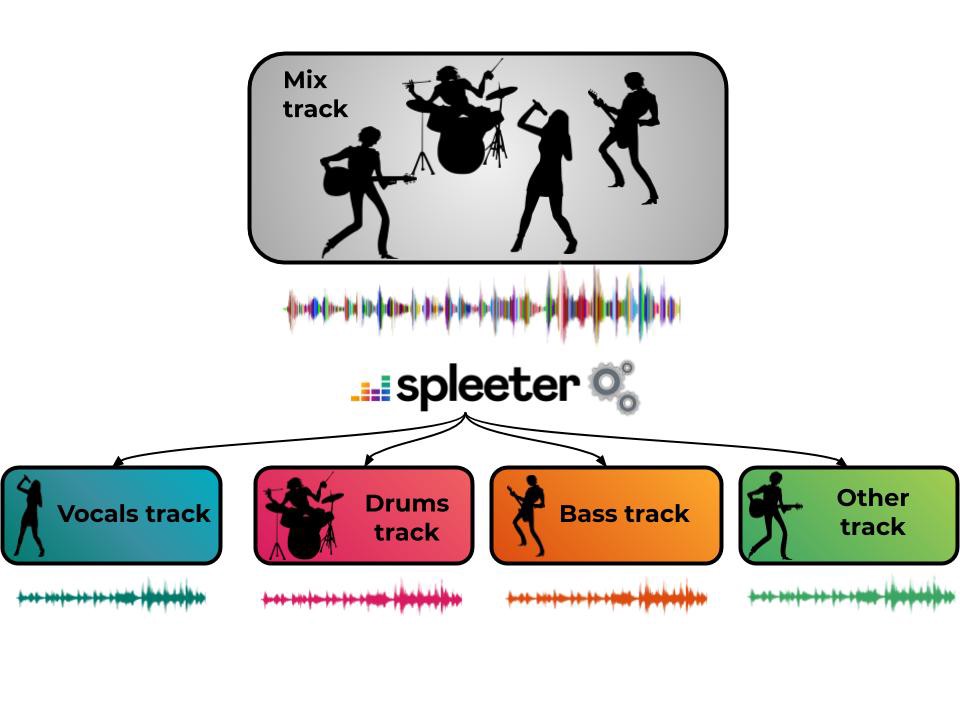
spleeter
知人が、Twitterで耳コピストに便利??と つぶやいていた記事があり

どうやら、バンド演奏の楽曲から、それぞれの音(ボーカル・ドラム・ベース・その他の楽器)に、分けるようです。
元記事は、こちらになるようで、Deezer.ioの一部の機能として発表されているようです。

フランスの会社で、音楽ストリーミング関係のAPI等を販売している会社のようですね。

で、元のGithubに行ってみました。
追記1/June/2021:Ver2.2.2まで来てますね. spleeter4maxというのも出てる。
Google Colab で体験できます。
あんまり難しいこと考えずに、これだけでいいかも(笑)
使い方は、上のをクリックして、実行していってくださいませ。
曲を変更するなら。
!wget https://github.com/deezer/spleeter/raw/master/audio_example.mp3
の行を変更するといいですね。
Google colab の Google Driveとの連携や ファイルのアップロードなどはこちらのファイルが参考になると思います。
spleeter自体のコマンドオプションは、これだけあります。
usage: spleeter separate [-h] [-a AUDIO_ADAPTER] [-p PARAMS_FILENAME]
[–verbose] -i AUDIO_FILENAMES [AUDIO_FILENAMES …]
[-o OUTPUT_PATH] [-n {directory,filename}]
[-d MAX_DURATION] [-c {wav,mp3,ogg,m4a,wma,flac}]
[-m]
オプションの説明
-h、-help このヘルプメッセージを表示して終了
-a AUDIO_ADAPTER、-adapter AUDIO_ADAPTER
オーディオI / Oに使用するオーディオアダプターの名前
-p PARAMS_FILENAME、
-params_filename PARAMS_FILENAME
パラメーターを含むJSONファイル名
--verbose詳細ログを表示します
-i AUDIO_FILENAMES [AUDIO_FILENAMES ...]、
-audio_filenames AUDIO_FILENAMES [AUDIO_FILENAMES ...]
入力オーディオファイル名のリスト
-o OUTPUT_PATH、-output_path OUTPUT_PATH
オーディオファイルを書き込む出力ディレクトリのパス
-n {ディレクトリ、ファイル名}、-output_naming {ディレクトリ、ファイル名}
出力ベースパスの名前の選択: "filename"
(入力ファイル名、つまり/path/to/audio/mix.wavを使用します
に分離されます
<output_path> / mix / <instument1> .wav、
<output_path> / mix / <instument2> .wav ...)または「ディレクトリ」
(入力最終レベルディレクトリの名前を使用します。
インスタンス/path/to/audio/mix.wavはに分離されます
<output_path> / audio / <instument1> .wav、
<output_path> / audio / <instument2> .wav)
-d MAX_DURATION、-max_duration MAX_DURATION
オーディオ処理の最大期間を設定します(入力ファイルの最初の数秒のmax_durationのみを分離します)
-c {wav、mp3、ogg、m4a、wma、flac}、-audio_codec {wav、mp3、ogg、m4a、wma、flac}
分離出力に使用されるオーディオコーデック
-m、-mwf 分離にマルチチャネルウィナーフィルタリングを使用するかどうか
例では、audio_example.mp3 という入力ファイルを、outputディレクトリに出力するってことですね。
!spleeter separate -i audio_example.mp3 -o output/
ちなみに、-p のところは分類する方法で、
2stems:ボーカル/伴奏に分類。
4stems:ボーカル/ドラム/ベース/その他の楽器
5stems:ボーカル/ドラム/ベース/ピアノ/その他の楽器
何曲かやってみました
フリーのバンド素材ってあんまり知らないんで。。小平で有名なBig市川さんの楽曲で(笑)
Happy Townという曲があります。ビデオは、こちら
このボーカルを取り出してみました。
どうです?ちゃんと切り出せていますね!
楽器の方も
すごい!カラオケができてますよ!!
Deep Learning恐るべし!!
Open Resources for Audio Source Separation
PythonとTensorflowを使ったDeeplearningで作られているようです。このプロジェクトすごくて。。 Opensourceのプロジェクトのようです。

詳しいことは、このページがすごい。なんと300個も引用文献があります。Audio souceの分離や、ストリーミングシグナル(時系列信号)の分離などの処理についての技術資料としてとても有益におもいました。

こちらにチュートリアルで、Google Colabで、機械学習のサンプルとしても、Pythonを使った音声処理や、信号処理の教材としても使えそうな内容です。

EUSIPCO 2019: Deep learning for music separation
論文形式でもダウンロードできます。
凄いですね。
← 一応、ファイルアップロード・ダウンロードの機能つけておきました。
しかし、この方法でいろいろできるってことは、いろんな信号処理やノイズ処理とかかなり進むんじゃないかな? 上司の声は聞こえないフィルターとか??(笑)
コメントを残していただけるとありがたいです